I resurrected my old call/ret experiments recently. I wish I had published more about how I did what I did 2 years ago — that’s why I started this blog, as a research journal, for my own benefit, for when I eventually return to a project after a lengthy hiatus. Fortunately, I emailed pretty thorough details to a fellow reverse engineer during the original project and still have the old email in the archives.
To refresh, the call/ret monitor watches a piece of code run and logs when function call or return instructions are executed, and where. After the fact, and combined with executable code that comes with meaningful symbol names, it generates a call graph to demonstrate where code really flows and gets around the problem of resolving indirect jumps in static disassembly listings. The original experiment assumes that for every call, there is an equal and opposite return (formally stated: num_calls == num_rets). The target I’m after right now behaves… differently. I am seeing way more calls than returns.
Obviously, there is a lot about compilers that I don’t understand. I think what I’m looking at in this situation is an artifact of C++ or perhaps its linkage from C. When I examine functions in static disassembly, there will be 7 NOP instructions after the stack frame initialization. Seems pretty innocuous. However, when I analyze the code more carefully while it’s running, I see that something — I suspect the dynamic loader — is using those 7 NOP bytes for something else. I imagine this is some common convention, and I would love to know more about it someday. But for the time being, I just want to get past this problem. In this particular situation, all that the patched code does is perform a call 5 bytes farther in the address space where a pop instruction is waiting to clear the return address that just got pushed on the stack by the call. So that’s where the massive call surplus comes from. Why the unknown entity couldn’t patch in an absolute jump is unclear.
Eventually, it dawned on me that the /ret half of the call/ret experiment was entirely unnecessary given the other data I already have. I have retooled the experiment with that in mind. It’s annoying to try to remember enough Perl to make this fly but it’s worth it for the resulting data visualization.
{kind=link}
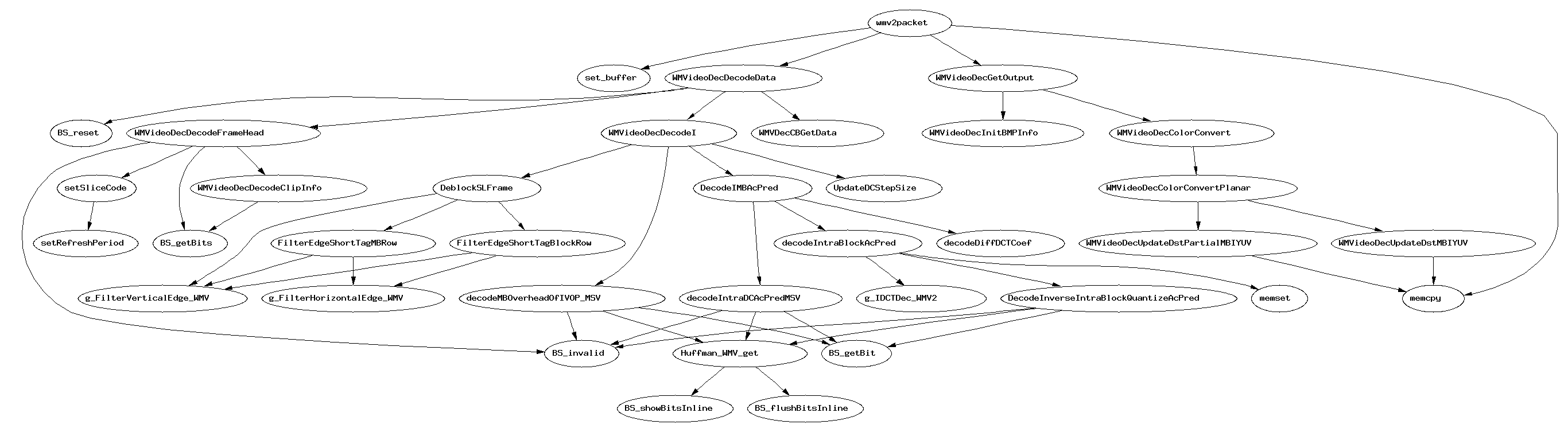{kind=link}
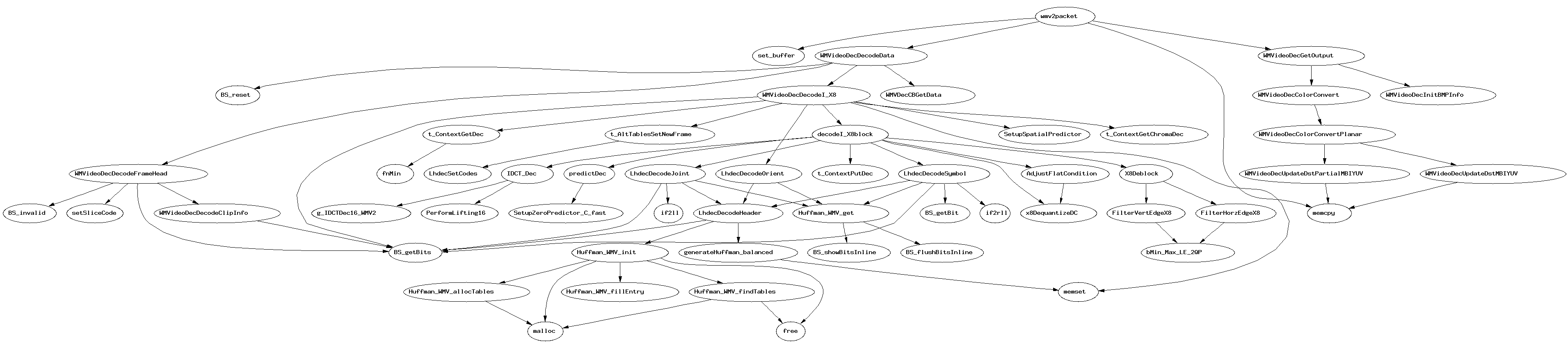{kind=link}
{kind=link}
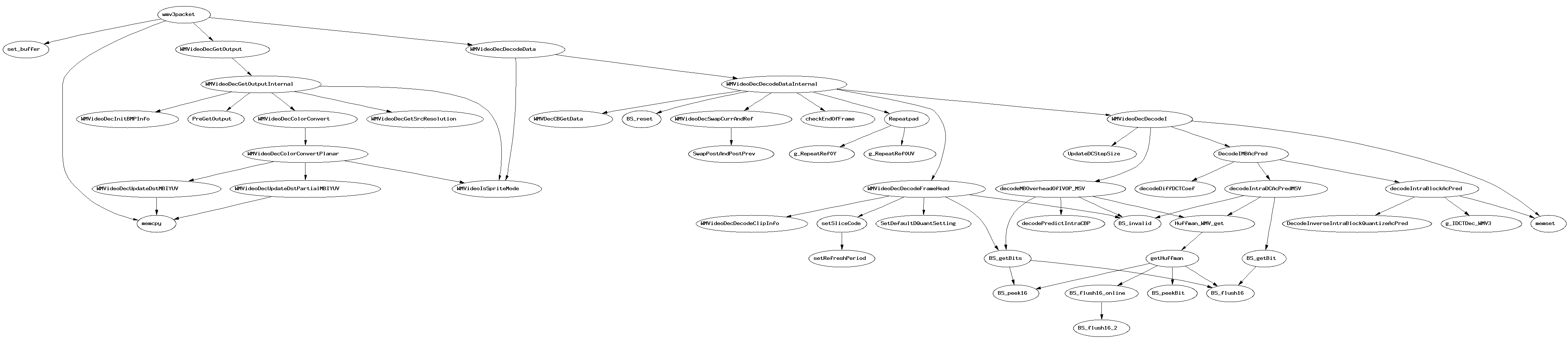{kind=link}