My Game Music Appreciation site allows users to interact with old video game music by toggling various channels, as long as the underlying synthesizer engine supports it.
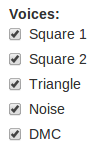
Users often find their way to the Nintendo DS section pretty quickly. This is when they notice an obnoxious quirk with the channel toggling feature: specifically, one channel doesn’t seem to map to a particular instrument or track.
When it comes to computer music playback methodologies, I have long observed that there are 2 general strategies: Fixed channel and dynamic channel allocation.
Fixed Channel Approach
One of my primary sources of computer-based entertainment used to be watching music. Sure I listened to it as well. But for things like Amiga MOD files and related tracker formats, there was a rich ecosystem of fun music playback programs that visualized the music. There exist music visualization modes in various music players these days (such as iTunes and Windows Media Player), but those largely just show you a single wave form. These files were real time syntheses based on multiple audio channels and usually showed some form of analysis for each channel. My personal favorite was Cubic Player:
Most of these players supported the concept of masking individual channels. In doing so, the user could isolate, study, and enjoy different components of the song. For many 4-channel Amiga MOD files, I observed that the common arrangement was to use the 4 channels for beat (percussion track), bass line, chords, and melody. Thus, it was easy to just listen to, e.g., the bass line in isolation.
MODs and similar formats specified precisely which digital audio sample to play at what time and on which specific audio channel. To view the internals of one of these formats, one gets the impression that they contain an extremely computer-centric view of music.
Dynamic Channel Allocation Algorithm
MODs et al. enjoyed a lot of popularity, but the standard for computer music is MIDI. While MOD and friends took a computer-centric view of music, MIDI takes, well, a music-centric view of music.
There are MIDI visualization programs as well. The one that came with my Gravis Ultrasound was called PLAYMIDI.EXE. It looked like this…

… and it confused me. There are 16 distinct channels being visualized but some channels are shown playing multiple notes. When I dug into the technical details, I learned that MIDI just specifies what notes need to be played, at what times and frequencies and using which instrument samples, and it was the MIDI playback program’s job to make it happen.
Thus, if a MIDI file specifies that track 1 should play a C major chord consisting of notes C, E, and G, it would transmit events “key-on C; delta time 0; key-on E; delta time 0; key-on G; delta time …; [other commands]”. If the playback program has access to multiple channels (say, up to 32, in the case of the GUS), the intuitive approach would be to maintain a pool of all available channels. Then, when it’s time to process the “key-on C” event, fetch the first available channel from the pool, mark it as in-use, play C on the channel, and return that channel to the pool when either the sample runs its course or the corresponding “key-off C” event is encountered in the MIDI command stream.
About That Game Music
Circling back around to my game music website, numerous supported systems use the fixed channel approach for playback while others use dynamic channel allocation approach, including evey Nintendo DS game I have so far analyzed.
Which approach is better? As in many technical matters, there are trade-offs either way. For many systems, the fixed channel approach is necessary because for many older audio synthesis systems, different channels had very specific purposes. The 8-bit NES had 5 channels: 2 square wave generators (used musically for melody/treble), 1 triangle wave generator (usually used for bass line), a noise generator (subverted for all manner of percussive sounds), and a limited digital channel (was sometimes assigned richer percussive sounds). Dynamic channel allocation wouldn’t work here.
But the dynamic approach works great on hardware with 16 digital channels available like, for example, the Nintendo DS. Digital channels are very general-purpose. What about the SNES, with its 8 digital channels? Either approach could work. In practice, most games used a fixed channel approach: Games might use 4-6 channels for music while reserving the remainder for various in-game sound effects. Some notable exceptions to this pattern were David Wise’s compositions for Rare’s SNES games (think Battletoads and the various Donkey Kong Country titles). These clearly use some dynamic channel approach since masking all but one channel will give you a variety of instrument sounds.
Epilogue
There! That took a long time to explain but I find it fascinating for some reason. I need to distill it down to far fewer words because I want to make it a FAQ on my website for “Why can’t I isolate specific tracks for Nintendo DS games?”
Actually, perhaps I should remove the ability to toggle Nintendo DS channels in the first place. Here’s a funny tale of needless work: I found the Vio2sf engine for synthesizing Nintendo DS music and incorporated it into the program. It didn’t support toggling of individual channels so I figured out a way to add that feature to the engine. And then I noticed that most Nintendo DS games render that feature moot. After I released the webapp, I learned that I was out of date on the Vio2sf engine. The final insult was that the latest version already supports channel toggling. So I did the work for nothing. But then again, since I want to remove that feature from the UI, doubly so.