Early last month, this thing called ORBX.js was in the news. It ostensibly has something to do with streaming video and codec technology, which naturally catches my interest. The hype was kicked off by Mozilla honcho Brendan Eich when he posted an article asserting that HD video decoding could be entirely performed in JavaScript. We’ve seen this kind of thing before using Broadway– an H.264 decoder implemented entirely in JS. But that exposes some very obvious limitations (notably CPU usage).
But this new video codec promises 1080p HD playback directly in JavaScript which is a lofty claim. How could it possibly do this? I got the impression that performance was achieved using WebGL, an extension which allows JavaScript access to accelerated 3D graphics hardware. Browsing through the conversations surrounding the ORBX.js announcement, I found this confirmation from Eich himself:
You’re right that WebGL does heavy lifting.
As of this writing, ORBX.js remains some kind of private tech demo. If there were a public demo available, it would necessarily be easy to reverse engineer the downloadable JavaScript decoder.
But the announcement was enough to make me wonder how it could be possible to create a video codec which effectively leverages 3D hardware.
Prior Art
In theorizing about this, it continually occurs to me that I can’t possibly be the first person to attempt to do this (or the ORBX.js people, for that matter). In googling on the matter, I found various forums and Q&A posts where people asked if it were possible to, e.g., accelerate JPEG decoding and presentation using 3D hardware, with no answers. I also found a blog post which describes a plan to use 3D hardware to accelerate VP8 video decoding. It was a project done under the banner of Google’s Summer of Code in 2011, though I’m not sure which open source group mentored the effort. The project did not end up producing the shader-based VP8 codec originally chartered but mentions that “The ‘client side’ of the VP8 VDPAU implementation is working and is currently being reviewed by the libvdpau maintainers.” I’m not sure what that means. Perhaps it includes modifications to the public API that supports VP8, but is waiting for the underlying hardware to actually implement VP8 decoding blocks in hardware.
What’s So Hard About This?
Video decoding is a computationally intensive task. GPUs are known to be really awesome at chewing through computationally intensive tasks. So why aren’t GPUs a natural fit for decoding video codecs?
Generally, it boils down to parallelism, or lack of opportunities thereof. GPUs are really good at doing the exact same operations over lots of data at once. The problem is that decoding compressed video usually requires multiple phases that cannot be parallelized, and the individual phases often cannot be parallelized. In strictly mathematical terms, a compressed data stream will need to be decoded by applying a function f(x) over each data element, x0 .. xn. However, the function relies on having applied the function to the previous data element, i.e.:
f(xn) = f(f(xn-1))
What happens when you try to parallelize such an algorithm? Temporal rifts in the space/time continuum, if you’re in a Star Trek episode. If you’re in the real world, you’ll get incorrect, unusuable data as the parallel computation is seeded with a bunch of invalid data at multiple points (which is illustrated in some of the pictures in the aforementioned blog post about accelerated VP8).
Example: JPEG
Let’s take a very general look at the various stages involved in decoding the ubiquitous JPEG format:
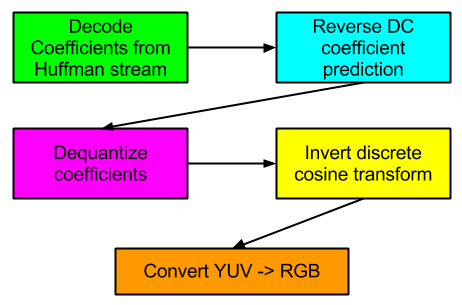
What are the opportunities to parallelize these various phases?
Continue reading

