When I started this FATE journey, the easiest approach for getting build results from a build client up to the FATE server was to use the direct MySQL protocol:
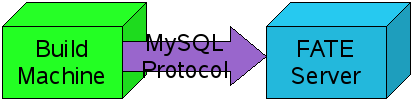
This is not an accepted way to do things in this day and age. It is more common to funnel the data via HTTP to the server. I resisted this at first because the direct database protocol method was working fine. But it seems that Python’s MySQLdb module is not portable to as many platforms as I would like to see FATE run on. At the same time, 8 months of FATE experience has shown the direct db protocol to be the weakest link of the whole endeavor. If connection is lost during the database operation, the whole script bails out with a Python exception and must be restarted manually. I realize that reading the MySQLdb-python documentation would probably allow me to deal gracefully with such failures and allow the script to continue. Another, more hackish solution would be to put the script in an infinite loop via the shell so that it would restart after a failure.
Here’s the thing: So what if I could handle the failure gracefully from within the Python script? What do I do then? After the script performs a build/test cycle, it is holding all the data in memory. So the script would just sit there holding the data until such time that it could access the database again. Meanwhile, more code needing testing is being checked into SVN. But the FATE script can only do one thing at a time.
So that’s when I got this idea to store the build/test data in a local database. What database? Would I have to establish a MySQL server on each build machine? Then I remembered hearing about this lighter-weight database called SQLite, for which Python has built-in support via its standard library (v2.5+).
So the idea was born: Store the build/test data locally and send the data to the main database when convenient. But just how would that work? My first impulse was a multi-process solution:
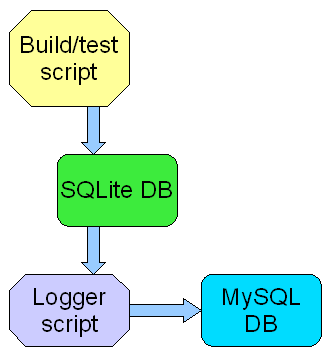
I decided it would be easier to organize everything in a single script. That implies a multi-threaded solution. But how to organize the process? Would the tester thread launch a logging thread? Vice versa? Perhaps a master thread to coordinate between the testing and logging operations?
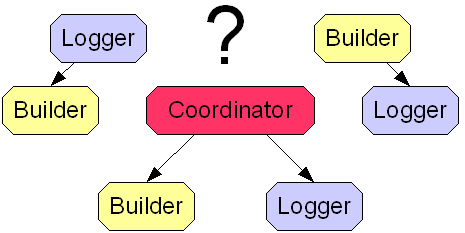
I should note that this thinking was predicated on the empirical data that indicated that the logging phase was painfully slow. Even though I optimized the logging process some months ago by eliminating a bunch of redundant data, it can still take an average of 15-20 seconds to log one build record and its 200 or so test result records. Building and testing does not require the network, while logging does not require the CPU, so parallelize these tasks. Or so I thought.
Then there is the matter of getting the data to the server. This has always been a hangup for me when thinking about this HTTP transport notion. I envisioned I would have to HTTP-POST the various bits of data comprising a record to the server and hope that the server responded each time or else I would have to start the “transaction” all over again.
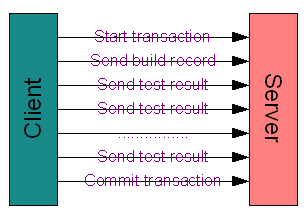
It might also be possible to encode all the data as separate POST fields somehow and send it all up at once. I worried that as the database grew, it might take an inordinate amount of time for the PHP script to finish its processing. After all, doing the direct protocol approach, the process could easily take more than 20 seconds to log data. The web server enforces hard limits on script processing time.
Then I had a revelation– SQLite, the missing serialization link.
How to send a build record and its test results? Create a new SQLite database file, store the build record and associated test results in it, and then send that file wholesale to the PHP script, which knows how to pull the data out and stuff it into the MySQL database.
I modified the main tester script to drop its results into an SQLite database file. Then I prototyped a separate script to pull the records from the database and send them to the server. Then I built the PHP script to receive the data. I was stunned that the entire transaction time (pull data from SQLite db, drop it in temporary file, run an HMAC authentication on the file, Base64- and URL-encode the data, send it via HTTP, decode it, authenticate the file, pull the data out, and dump it into MySQL) took only 2-3 seconds!
This vastly simplified the script since I discarded the multi-thread/process idea. This is the new model, and the way FATE currently operates:
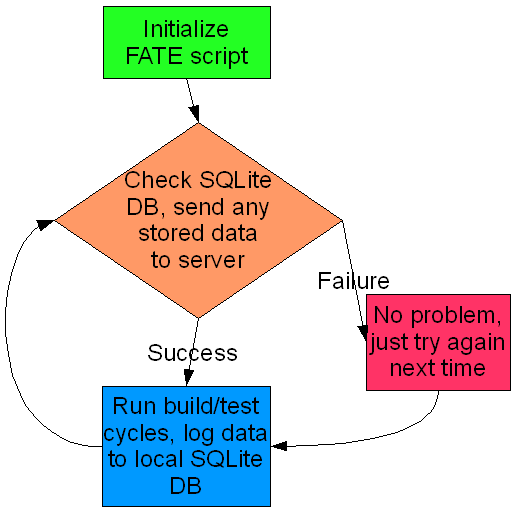
In this model, the build/test script doesn’t retain any result data in memory– it all goes into the local SQLite db immediately. When a build/test cycle is finished, it attempts to send the results to the FATE server. If something, anything, goes wrong, no big deal, just proceed to the next build/test cycle. At the end of that cycle, try to log the most recent data, as well as the set that is still hanging around from before.
After coming up with this use case for SQLite, I realized that this lightweight database could serve perfectly well as the serialization format between 2 languages, such as PHP and Python. Problem: I maintain the FATE test specifications via a PHP script. When I update specs, if I want them to be available to the FATE build clients, I have to use a Python script that accesses the MySQL database, fetches the test specs, and serializes the specs using Python’s pickle serialization. Then I have to manually upload that pickled file to the server. It would be nice if PHP would update the test spec file when a test spec is updated, but that requires a common serialization format between PHP and Python. And don’t even talk to me about XML.
Hello SQLite. Next TODO item is to revise the FATE system so that the test specs are transported via SQLite database rather than Python’s pickling format. Maybe other people can find good uses for the test spec file in such an accessible format.
1. How to handle errors – read http://www.python.org/doc/2.5.2/tut/node10.html
2. About SQLite – the only good thing is that driver is the database server itself.
It’s horribly slow for DB-intensive for practical tasks (I’ve tried using it in my app for master thesis but found out that using PostgreSQL increased performance in many times). But using SQLite for intermediate data representation is an interesting hack indeed.
I don’t doubt your performance (or lack thereof) claims. Fortunately, they don’t effect this use case. I have before and after numbers for SQLite pertaining to this task and SQLite has an immeasurable impact on the overall build/test operation. I was a little worried that constantly opening and closing the database connection would impact performance, but for this application, it doesn’t matter.
Also, I do know about handling Python exceptions. The script already copes gracefully with HTTP problems. Well, ‘gracefully’ might be a strong word, but at least the script doesn’t fall flat when it bumps into an HTTP problem, like it did with MySQL mishaps. That was another reason I wanted to move over to an HTTP-based transport mechanism.
Low performance in SQLite is usually due to the fact that it fsync()s 3 times per transaction to guarantee data integrity. So if you INSERT 50 rows, that’s 150 flushes to disk.
To aggravate matters further, it turns out that on most filesystems in Linux trying to sync a single file actually flushes all system buffers.
What can be done?
* Disable syncs entirely (“PRAGMA synchronous = OFF;” every time just after opening the DB, before starting writes to it). This can easily boost performance over a couple orders of magnitude, and you’re still safe against application crashes. OS crashes or power loss can corrupt the DB though.
* Batch statements that update the DB (INSERT, UPDATE…) in transactions (“BEGIN TRANSACTION;” … “COMMIT TRANSACTION;”). That way only 3 fsyncs total are required per transaction, not per statement, and you also take benefit of multi-statement atomicity, so all the changes make it to disk or none does. This can make a lot of difference – if you enclose all operations in a transaction, you only need to sync once (well, thrice) per run. Even if you disabled syncs, this will still boost speed a lot, since some stuff can be batched together better.
Firefox3 hit this problem hard, see:
http://shaver.off.net/diary/2008/05/25/fsyncers-and-curveballs/
https://bugzilla.mozilla.org/show_bug.cgi?id=421482
But with some care it can be made very performant (specially if you don’t care about corruption – some people just auto-backup the DBs on startup and run syncless). I’ve seen SQLite import about 200000 rows unto a DB in well under a second on commodity hardware, so I’d say performance isn’t exactly its weakest part.
Thanks for the feedback, Anonymous. Indeed, I have finally been observing some performance problems that I suspect are SQLite’s fault (my new system for regenerating a test spec cache file via a PHP script). It takes several seconds to insert only 230 or so rows. However, I recognize that the PHP interface I am using is probably configured by default to treat every individual INSERT as a transaction which incurs the penalties you have outlined.
Unfortunately, the test cache regeneration is performed so infrequently that I have little incentive to research optimization. The mystery isn’t likely to be solved until I open source it and see my code on thedailywtf.com sometime later.
To follow up: I optimized the test cache regeneration with a startTransaction() and a commit() as defined by PHP’s PDO model. The total regeneration time went from between 10-30 seconds down to more or less instantaneous.