This is part 2 of the adventure started in my Subtitling Sierra VMD Files post. After I completed the VMD subtitling, The Translator discovered a wealth of animation files in a format called RBT (this apparently stands for “Robot” but I think “Ribbit” format could be more fun). What are we going to do? We had come so far by solving the VMD subtitling problem for Phantasmagoria. It would be a shame if the effort ground to a halt due to this.
Fortunately, the folks behind the ScummVM project already figured out enough of the format to be able to decode the RBT files in Phantasmagoria.
In the end, I was successful in creating a completely standalone tool that can take a Robot file and a subtitle file and create a new Robot file with subtitles. The source code is here (subtitle-rbt.c). Here’s what the final result looks like:

“What’s in the refrigerator?” I should note at this juncture that I am not sure if this particular Robot file even has sound or dialogue since I was conducting these experiments on a computer with non-working audio.
The RBT Format
I have created a new MultimediaWiki page describing the Robot Animation format based on the ScummVM source code. I have not worked with a format quite like this before. These are paletted animations which consist of a sequence of independent frames that are designed to be overlaid on top of static background. Because of these characteristics, each frame encodes its own unique dimensions and origin coordinate within the frame. While the Phantasmagoria VMD files are usually 288×144 (which are usually double-sized for the benefit of a 640×400 Super VGA canvas), these frames are meant to be plotted on a game field that was roughly 576×288 (288×144 doublesized).
For example, 2 minimalist animation frames from a desk investigation Robot file:

100×147

101×149
As for compression, my first impression was that the algorithm was the same as VMD. This is wrong. It evidently uses an unmodified version of a standard algorithm called Lempel-Ziv-Stac (LZS). It shows up in several RFCs and was apparently used in MS-DOS’s transparent disk compression scheme.
Approach
Thankfully, many of the lessons I learned from the previous project are applicable to this project, including: subtitle library interfacing, subtitling in the paletted colorspace, and replacing encoded frames from the original file instead of trying to create a new file.
Here is the pitch for this project:
- Create a C program that can traverse through an input file, piece by piece, and generate an output file. The result of this should be a bitwise identical file.
- Adapt the LZS compression decoding algorithm from ScummVM into the new tool. Make the tool dump raw Portable NetMap (PNM) files of varying dimensions and ensure that they look correct.
- Compress using LZS.
- Stretch the frames and draw subtitles.
- More compression. Find the minimum window for each frame.
Compression
Normally, my first goal is to decompress the video and store the data in a raw form. However, this turned out to be mathematically intractable. While the format does support both compressed and uncompressed frames (even though ScummVM indicates that the uncompressed path is yet unexercised), the goal of this project requires making the frames so large that they overflow certain parameters of the file.
A Robot file has a sequence of frames and 2 tables describing the size of each frame. One table describes the entire frame size (audio + video) while the second table describes just the video frame size. Since these tables only use 16 bits to specify a size, the maximum frame size is 65536 bytes. Leaving space for the audio portion of the frame, this only leaves a per-frame byte budget of about 63000 bytes for the video. Expanding the frame to 576×288 (165,888 pixels) would overflow this limit.
Anyway, the upshot is that I needed to compress the data up front.
Fortunately, the LZS compressor is pretty straightforward, at least if you have experience writing VLC-oriented codecs. While the algorithm revolves around back references, my approach was to essentially write an RLE encoder. My compressor would search for runs of data (plentiful when I started to stretch the frame for subtitling purposes). When a run length of n=3 or more of the same pixel is found, encode the pixel by itself, and then store a back reference of offset -1 and length (n-1). It took a little while to iron out a few problems, but I eventually got it to work perfectly.
I have to say, however, that the format is a little bit weird in how it codes very large numbers. The length encoding is somewhat Golomb-like, i.e., smaller values are encoded with fewer bits. However, when it gets to large numbers, it starts encoding counts of 15 as blocks of 1111. For example, 24 is bigger than 7. Thus, emit 1111 into the bitstream and subtract 8 from 23 -> 16. Still bigger than 15, so stuff another 1111 into the bitstream and subtract 15. Now we’re at 1, so stuff 0001. So 24 is 11111111 0001. 12 bits is not too horrible. But the total number of bytes ~ (value / 30). So a value of 300 takes around 10 bytes (80 bits) to encode.
Palette Slices
As in the VMD subtitling project, I took the subtitle color offered in the subtitle spec file as a suggestion and used Euclidean distance to match to the closest available color in the palette. One problem, however, is that the palette is a lot smaller in these animations. According to my notes, for the set of animations I scanned, only about 80 colors were specified, starting at palette index 55. I hypothesize that different slices of the palette are reserved for different uses. E.g., animation, background, and user interface. Thus, there is a smaller number of colors to draw upon for subtitling purposes.
Scaling
One bit of residual weirdness in this format is the presence of a per-frame scale factor. While most frames set this to 100 (100% scale), I have observed 70%, 80%, and 90%. ScummVM is a bit unsure about how to handle these, so I am as well. However, I eventually realized I didn’t really need to care, at least not when decoding and re-encoding the frame. Just preserve the scale factor. I intend to modify the tool further to take scale factor into account when creating the subtitle.
The Final Resolution
Right around the time that I was composing this post, The Translator emailed me and notified me that he had found a better way to subtitle the Robot files by modifying the scripts, rendering my entire approach moot. The result is much cleaner:
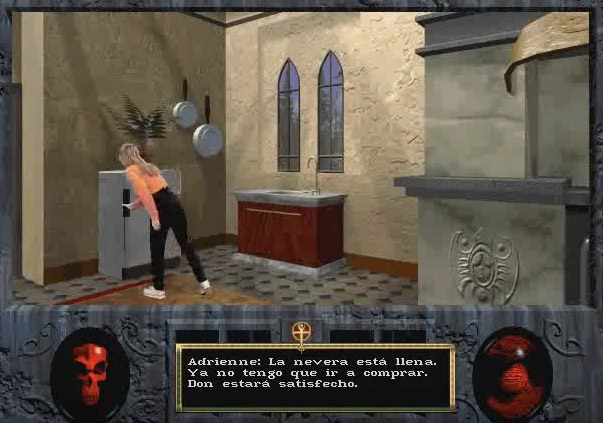
Turns out that the engine supported subtitles all along
It’s a good thing that I enjoyed the challenge or I might be annoyed at this point.
See Also
- Subtitling Sierra VMD Files: My effort to subtitle the main FMV files found in Sierra games.
I still insist that random variable-length codes should not be attributed to Golomb. Especially in LZStac case where codes don’t really have regular structure (and they are closer to start-step-stop codes really).
As for compression itself, the problem nowadays is either to find matching segments fast (usually using a hashtable) or to find optimal segmenting for the stream so it can be compressed the best (that is complicated by different costs of coding matches depending on what you coded before and such). But a simple brute force search is nothing bad in your situation since both the window and data amounts are small.
Overall, this one is even more impressive than your VMD work.
@Kostya: I was speculating on methods for doing better back reference searches and a hashtable was the first thing I thought of. I figured there must be better methods (the first thing I think of is never the best option, after all).
I updated the post after your comment– impressive as this might have been, it was mooted when The Translator figured out how to subtitle the Robot files via the engine itself. So I guess that brings this work to a close. VMD subtitling is still relevant, fortunately.
If you need LZS decompression code and don’t want to rip it from ScummVM, you can use my old implementation from this page: http://vagsoft.chat.ru/sci.html (it’s inside SCI Resource Dumper tool).
Sierra used same (de)compression library to pack game’s resources inside ressci.* files.
Hello!
If you still have some steam I suggest you have a look at the “pull” request currently existing in the ScummVM source code, and implement your RBT and VMD decoders. That would help them adding Phantasmagoria to the supported games.
@M.B. That sounds like it would be a good entry point into ScummVM development (I have a bunch of games I would like to implement in the project). Strangely, I assumed that Phantasmagoria was already supported since I used ScummVM to reverse engineer a description of the RBT format. But I guess not.
I assume this is the pull request you are referring to:
https://github.com/scummvm/scummvm/pull/805
I don’t really see what I can with on that one.