Version 32 of Google’s Chrome web browser introduced this nifty feature:
When a browser tab has an element that is producing audio, the browser’s tab shows the above audio notification icon to inform the user. I have seen that people have a few questions about this, specifically:
- How does this feature work?
- Why wasn’t this done sooner?
- Are other browsers going to follow suit?
Short answers: 1) Chrome offers a new plugin API that the Flash Player is now using, as are Chrome’s internal media playing facilities; 2) this feature was contingent on the new plugin infrastructure mentioned in the previous answer; 3) other browsers would require the same infrastructure support.
Longer answers follow…
Plugin History
Plugins were originally based on the Netscape Plugin API. This was developed in the early 1990s in order to support embedding PDFs into the Netscape web browser. The NPAPI does things like providing graphics contexts for drawing and input processing, and mediate network requests through the browser’s network facilities.
What NPAPI doesn’t do is handle audio. In the early-mid 1990s, audio support was not a widespread consideration in the consumer PC arena. Due to the lack of audio API support, if a plugin wanted to play audio, it had to go outside of the plugin framework.
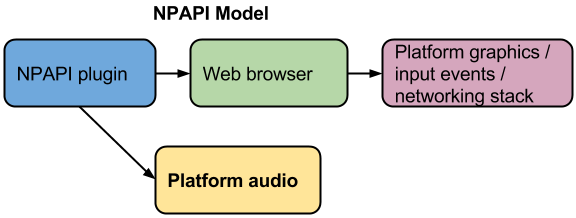
There are a few downsides to this approach:
- If a plugin wants to play audio, it needs to access unique audio APIs on each supported platform. One of the most famous things I’ve ever written deals concerns this nightmare on Linux. (The picture worth a thousand words.)
- Plugin necessarily needs free unrestricted access to system facilities, i.e., security measures like sandboxing become more difficult without restricting functionality.
- Since the browser doesn’t mediate access to the audio APIs, the browser can’t reasonably be expected to know when a plugin is accessing the audio resources.
So that last item hopefully answers the question of why it has been so difficult for NPAPI-supporting browsers to implement what seems like it would be simple functionality, like implementing a per-tab audio notifier.
Plugin Future
Since Google released Chrome in an effort to facilitate advancements on the client side of the internet, they have made numerous efforts to modernize various legacy aspects of web technology. These efforts include the SPDY protocol, Native Client, WebM/WebP, and something call the Pepper Plugin API (PPAPI). This is a more modern take on the classic plugin architecture to supplant the aging NPAPI:

Right away, we see that the job of the plugin writer is greatly simplified. Where was this API years ago when I was writing my API jungle piece?
The Linux version of Chrome was apparently the first version that packaged the Pepper version of the Flash Player (doing so fixed an obnoxious bug in the Linux Flash Player interaction with GTK). Now, it looks like Windows and Mac have followed suit. Digging into the Chrome directory on a Windows 7 installation:
AppData\Local\Google\Chrome\Application\[version]\PepperFlash\pepflashplayer.dll
This directory exists for version 31 as well, which is still hanging around my system.
So, to re-iterate: Chrome has a new plugin API that plugins use to access the audio API. Chrome knows when the API is accessed and that allows the browser to display the audio notifier on a tab.
Other Browsers
What about other browsers? “Mozilla is not interested in or working on Pepper at this time. See the Chrome Pepper pages.”


{kind=link}