I know I’m not the only person to have the idea to port a media player to the Sega Dreamcast video game console. But I did make significant progress on an implementation. I’m a little surprised to realize that I haven’t written anything about it on this blog yet, given my propensity for publishing my programming misadventures.

This old effort had been on my mind lately due to its architectural similarities to something else I was recently brainstorming.
Early Days
Porting a multimedia player was one of the earliest endeavors that I embarked upon in the multimedia domain. It’s a bit fuzzy for me now, but I’m pretty sure that my first exposure to the MPlayer project in 2001 arose from looking for a multimedia player to port. I fed it through the Dreamcast development toolchain but encountered roadblocks pretty quickly. However, this got me looking at the MPlayer source code and made me wonder how I could contribute, which is how I finally broke into practical open source multimedia hacking after studying the concepts and technology for more than a year at that point.
Eventually, I jumped over to the xine project. After hacking on that for awhile, I remembered my DC media player efforts and endeavored to compile xine to the console. The first attempt was to simply compile the codebase using the Dreamcast hobbyist community’s toolchain. This is when I came to fear the multithreaded snake pit in xine’s core. Again, my memories are hazy on the specifics, but I remember the engine having a bunch of threading hacks with comments along the lines of “this code deadlocks sometimes, so on shutdown, monitor this lock and deliberately break it if it has been more than 3 seconds”.
Something Workable
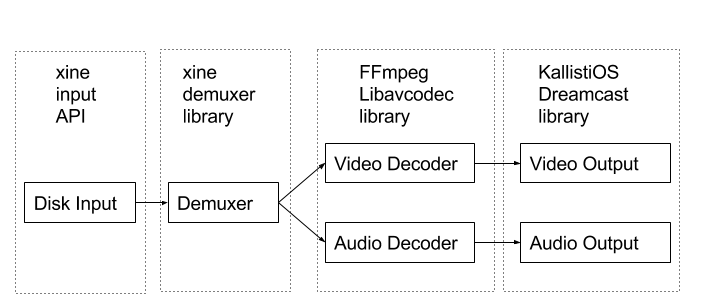
Eventually, I settled on a combination of FFmpeg’s libavcodec library for audio and video decoders, xine’s demuxer library, and xine’s input API, combined with my own engine code to tie it all together along with video and output drivers provided by the KallistiOS hobbyist OS for Dreamcast. Here is a simple diagram of the data movement through this player:
Details and Challenges
This is a rare occasion when I actually got to write the core of a media player engine. I made some mistakes.
xine’s internal clock ran at 90000 Hz. At least, its internal timestamps were all in reference to a 90 kHz clock. I got this brilliant idea to trigger timer interrupts at 6000 Hz to drive the engine. Whatever the timer facilities on the Dreamcast, I found that 6 kHz was the greatest common divisor with 90 kHz. This means that if I could have found an even higher GCD frequency, I would have used that instead.
So the idea was that, for a 30 fps video, the engine would know to render a frame on every 200th timer interrupt. I eventually realized that servicing 6000 timer interrupts every second would incur a ridiculous amount of overhead. After that, my engine’s philosophy was to set a timer to fire for the next frame while beginning to process the current frame. I.e., when rendering a frame, set a timer to call back in 1/30th of a second. That worked a lot better.
As I was still keen on 8-bit paletted image codecs at the time (especially since they were simple and small for bootstrapping this project), I got to use output palette images directly thanks to the Dreamcast’s paletted textures. So that was exciting. The engine didn’t need to convert the paletted images to a different colorspace before rendering. However, I seem to recall that the Dreamcast’s PowerVR graphics hardware required that 8-bit textures be twiddled/swizzled. Thus, it was still required to manipulate the 8-bit image before rendering.
I made good progress on this player concept. However, a huge blocker for me was that I didn’t know how to make a proper user interface for the media player. Obviously, programming the Dreamcast occurred at a very low level (at least with the approach I was using), so there were no UI widgets easily available.
This was circa 2003. I assumed there must have been some embedded UI widget libraries with amenable open source licenses that I could leverage. I remember searching and checking out a library named libSTK. I think STK stood for “set-top toolkit” and was positioned specifically for doing things like media player UIs on low-spec embedded computing devices. The domain hosting the project is no longer useful but this appears to be a backup of the core code.
It sounded promising, but the libSTK developers had a different definition of “low-spec embedded” device than I did. I seem to recall that they were targeting something along with likes of a Pentium III clocked at 800 MHz with 128 MB RAM. The Dreamcast, by contrast, has a 200 MHz SH-4 CPU and 16 MB RAM. LibSTK was also authored in C++ and leveraged the Boost library (my first exposure to that code), and this all had the effect of making binaries quite large while I was trying to keep the player in lean C.
Regrettably, I never made any serious progress on a proper user interface. I think that’s when the player effort ran out of steam.
The Code
So, that’s another project that I never got around to finishing or publishing. I was able to find the source code so I decided to toss it up on github, along with 2 old architecture outlines that I was able to dig up. It looks like I was starting small, just porting over a few of the demuxers and decoders that I knew well.
I’m wondering if it would still be as straightforward to separate out such components now, more than 13 years later?