One nice thing about H.264 is that its transforms are specified to be bit exact. That makes it straightforward to test. Given a compressed sample and its reference stream, your decoder is expected to produce output that matches the reference stream, bit for bit. Microsoft VC-1 is the same way and I suspect that RealVideo 3, RealVideo 4, and Sorenson Video 3 — all of which were proprietary forerunners of the H.264 lineage — express the same characteristic.
So H.264 lends itself well to automated testing, such as the type that FATE subjects it to. Unfortunately, certain other codecs don’t conform well to this model. You may have heard of a few: video codecs such as MPEG-1, MPEG-2, MPEG-4, H.261, H.263, and anything else that uses the same 8×8 discrete cosine transform. Michael thoroughly and visually explains the problem in a blog post.
3 strategies for automatically testing in the face of such adversity:
- Maintain one test spec in the database for a particular sample. Test it by comparing it to a reference video stream by using a custom tool that will yield a yea or nay answer indicating if the test output was within an acceptable threshold (perhaps using FFmpeg’s existing tiny_psnr utility, if it can return such concise information). Pros: No modification needed for the fundamental FATE infrastructure. Cons: Requires a lot of raw test media in the formal FATE suite, which is not good considering my future plans to expand the infrastructure to make it easy for other people to rsync the suite and test it locally. Also, I don’t know how to properly compare the data. If I understand the problem correctly, a keyframe with problems will only have various individual samples off by 1. But the error can compound over a sequence of many frames.
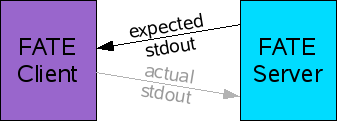
- Maintain one test spec in the database for a particular sample, but with multiple possible expected stdout text blobs. This would somehow tie expected stdout blobs to certain configurations. Pros: Less storage required for FATE suite and test can maintain bit exactness. Cons: Requires infrastructure modification.
- Maintain multiple test specs in the database, each of which correspond to different possible outputs; extend the infrastructure to include test groups. Particular configurations are assigned to run all the tests in a particular group. This is an idea that I think I will need to implement eventually anyway. For example, I can imagine some alternate test methodology for validating FFmpeg, or more likely, libavcodec and libavformat, on certain embedded environments which won’t be able to run ‘ffmpeg’ directly from any sort of command line. Pros: Same as strategy #2. Plus, implementing an idea whose time will probably come anyway. Cons: Same as strategy #2.
I am sort of leaning towards strategy #2 right now. As a possible implementation, the test_spec table might be extended to have 2 expected_stdout fields that are sent to a FATE build/test machine. The machine tests the actual stdout against both sets of expected stdout text and sends the server a code to indicate how the test turned out. Code 1 or 2 means expected stdout 1 or 2 matched, respectively; code 0 means that neither match, and the actual stdout will be sent for storage (also used in case both expected stdout fields were NULL for “don’t care”). So this infrastructure revision can occur at the same time as the one discussed in the previous post.
There’s no reason that this solution can’t co-exist with the grouping idea proposed in strategy #3 when that is implemented. I think grouping will be more useful for completely different platforms with completely different testing programs (‘ffmpeg’ vs. something else for embedded tests), rather than in cases where the command line is exactly the same but various platform results are subtly different.
The biggest benefit for strategies 2 and 3 should be in keeping the size of the FATE suite small. Deploying one of these solutions should also help in automatically testing many perceptual audio codecs (think MP3, AAC, Vorbis, AC3, DTS, etc.) which will also not be bit exact among platforms.
Here’s one big question I have regarding strategy #2: How many expected stdout fields should the database provide for? Is it enough to have 2 different expected stdout fields? 3? More? Should I just go all out and make it a separate table? Yeah, that would probably be the best solution.
I admit, I still don’t completely understand the issues involving the bit inexactness of the decoding processes. Does it vary among processors? Depending upon little vs. big endian? Is it dependent upon C library? Some empirical tests are in order. An impromptu decode of a random MP3 file using FFmpeg yields bit identical PCM data for x86_32, x86_64, and PPC builds of FFmpeg (x86_32 built with both gcc and icc). I guess this makes sense. Bit inexactness for perceptual audio would arise from floating point rounding discrepancies which, per my understanding, are affected by C library. Since this is all Linux, no problem. If I got FFmpeg compiled on Windows, I suspect there would be discrepancies.
I tested a random MJPEG file (THP file, actually), and the frames are the same on x86_32 and x86_64, but different on PPC. So that’s one example of where I will need to employ one of the 3 strategies outlined above.