The best type of compression is to encode no data at all.
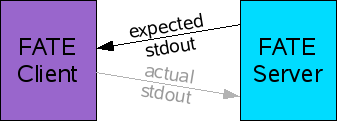
I’m a little embarrassed to admit that this didn’t occur to me until just now, 2 months after I first deployed the FATE Server. Each test specification in the database has an expected stdout text blob associated with it. The server sends this to the client, who compares the expected stdout with the actual stdout gathered from running a test. The client then sends the actual stdout text back to the server.
Wait! There’s no reason to send the actual stdout back to the server. At least, not if the test was successful. Logically, that means that (actual stdout) == (expected stdout). Send back a special code to indicate that the stdout matched. The server can decide to clone the expected stdout into the actual stdout column in the database under that condition.
Wait, #2! There’s no reason to store the actual stdout if the test is successful. Logically, it’s the same as the data that’s already sitting in the expected stdout field. Which, BTW, is only in the database once. Whereas, actual stdout data occurs many times in a different table.
As you can see, I have been considering optimization strategies. After a client is finished running all the tests for a given configuration, it logs the results for all the tests. There are presently only 90 tests and it seems to take about 30 seconds, give or take 10, to log all the results. That’s a measly 3 records per second, which is annoying, especially since I want this suite to embody hundreds upon hundreds of individual tests eventually. This issue is sort of blocking me from really ramping up on the number of test cases.
Right now. the test clients use the direct MySQL protocol through Python and I doubt that it is being compressed over the wire. I hope to revise the infrastructure so that the test results will be serialized, compressed, and sent to a CGI script on the FATE server. The CGI script will decompress, deserialize, and enter the test results from a position much closer to the actual database server. Hopefully, this will improve performance. If nothing else, it will set the stage for running the FATE client on machines that don’t have working Python MySQLdb libraries, or that can’t access the MySQL port directly due to firewalling.
So that will hopefully address the bandwidth concerns. There is still the issue of disk storage. As discussed previously, raw disk space is really not an issue. I could swallow a gigabyte or 2 per month and still be okay for several years. But it would still be nice for the database to remain a manageable size for the purpose of responsible backups. The idea of not storing actual stdout, rather just a bool to indicate that it checked out, will help to reduce storage requirements. However, I think I should also institute a schedule of “retiring” the stdout/stderr data from old build records and test results.
Someone showed up on ffmpeg-devel yesterday with a bug report that ‘ffmpeg -h’ crashes the program on Solaris. It seems quite reasonable to add a test spec for that simple case with a NULL for expected stdout which would indicate “don’t care”. I would be concerned about filling up so much space with the help command (stdout on ‘ffmpeg -h’ is presently about 28K) on each run. But I might not mind so much if I could retire (ruthlessly delete) the data later.
Maybe storing a diff between the expected and actually output is even beter? If they are identical, the diff will be zero bytes. If not, you may still get some compression out of it, though for cases where they diverge too much, you’re of course better off storing the actual output directly.
Good idea. As you suspect, however, there is a lot of divergence, especially if this is going line by line. Each line contains a CRC so if even 1 bit is different than expected, the whole line is different (as CRC is expected to do).
I was reading that post, and thought of a another idea: there is no need to send the stdout to the client, you can just send its md5sum! If it mismatches, then the client send the full stdout to the server.
Hey, that’s a good idea, Vitor. I had not considered that. I had considered piping all the CRC data through md5sum for the purpose of making the total stdout much more condensed. But I still want to retain the framecrc text since that might be valuable for developers debugging problems that occur on platforms they don’t have.
But your idea is a good optimization. I have some yet more optimizations in mind and I might be able to make this one work with those.