Some time ago, Diego “Flameeyes” Pettenò tried his hand at reverse engineering a set of really old CD-ROMs containing even older Italian literature. The goal of this RE endeavor would be to extract the useful literature along with any structural metadata (chapters, etc.) and convert it to a more open format suitable for publication at, e.g., Project Gutenberg or Archive.org.
Unfortunately, the structure of the data thwarted the more simplistic analysis attempts (like inspecting for blocks of textual data). This will require deeper RE techniques. Further frustrating the effort, however, is the fact that the binaries that implement the reading program are written for the now-archaic Windows 3.1 operating system.
In pursuit of this RE goal, I recently thought of a way to glean more intelligence using DOSBox.
Prior Work
There are 6 discs in the full set (distributed along with 6 sequential issues of a print magazine named L’Espresso). Analysis of the contents of the various discs reveals that many of the files are the same on each disc. It was straightforward to identify the set of files which are unique on each disc. This set of files all end with the extension “LZn”, where n = 1..6 depending on the disc number. Further, the root directory of each disc has a file indicating the sequence number (1..6) of the CD. Obviously, these are the interesting targets.
The LZ file extensions stand out to an individual skilled in the art of compression– could it be a variation of the venerable LZ compression? That’s actually unlikely because LZ — also seen as LIZ — stands for Letteratura Italiana Zanichelli (Zanichelli’s Italian Literature).
The Unix ‘file’ command was of limited utility, unable to plausibly identify any of the files.
Progress was stalled.
Saying Hello To An Old Frenemy
I have been showing this screenshot to younger coworkers to see if any of them recognize it:
Not a single one has seen it before. Senior computer citizen status: Confirmed.
I recently watched an Ancient DOS Games video about Windows 3.1 games. This episode showed Windows 3.1 running under DOSBox. I had heard this was possible but that it took a little work to get running. I had a hunch that someone else had probably already done the hard stuff so I took to the BitTorrent networks and quickly found a download that had the goods ready to go– a directory of Windows 3.1 files that just had to be dropped into a DOSBox directory and they would be ready to run.
Aside: Running OS software procured from a BitTorrent network? Isn’t that an insane security nightmare? I’m not too worried since it effectively runs under a sandboxed virtual machine, courtesy of DOSBox. I suppose there’s the risk of trojan’d OS software infecting binaries that eventually leave the sandbox.
Using DOSBox Like ‘strace’
strace is a tool available on some Unix systems, including Linux, which is able to monitor the system calls that a program makes. In reverse engineering contexts, it can be useful to monitor an opaque, binary program to see the names of the files it opens and how many bytes it reads, and from which locations. I have written examples of this before (wow, almost 10 years ago to the day; now I feel old for the second time in this post).
Here’s the pitch: Make DOSBox perform as strace in order to serve as a platform for reverse engineering Windows 3.1 applications. I formed a mental model about how DOSBox operates — abstracted file system classes with methods for opening and reading files — and then jumped into the source code. Sure enough, the code was exactly as I suspected and a few strategic print statements gave me the data I was looking for.
Eventually, I even took to running DOSBox under the GNU Debugger (GDB). This hasn’t proven especially useful yet, but it has led to an absurd level of nesting:
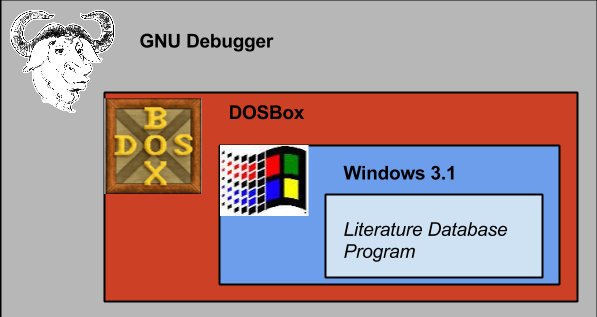
The target application runs under Windows 3.1, which is running under DOSBox, which is running under GDB. This led to a crazy situation in which DOSBox had the mouse focus when a GDB breakpoint was triggered. At this point, DOSBox had all desktop input focus and couldn’t surrender it because it wasn’t running. I had no way to interact with the Linux desktop and had to reboot the computer. The next time, I took care to only use the keyboard to navigate the application and trigger the breakpoint and not allow DOSBox to consume the mouse focus.
New Intelligence
Continue reading →



