I should do a followup to the VP3 golden frame encoding brainstorm while this stuff is still fresh on the brain. Let’s talk about a possible approach for encoding VP3 (and again, by extension, Theora) interframes. Along the way, I’ll discuss the parts that (I hope) can be handled by FFmpeg’s internal facilities.
A VP3 golden frame only encodes a header followed by a coefficient bitstream. An interframe contains a header, several segments describing which superblocks, macroblocks, and fragments in the frame are coded and how, a segment for motion vector data, and finally, the coefficient bitstream. Note that the interframe is concerned with the notion of a macroblock — 2×2 Y fragments + 1 U fragment + 1 V fragment, the same as the traditional JPEG/MPEG concept — whereas the golden frame does not care about macroblocks. This is because motion vectors operate on a per-macroblock basis.
Rough outline– for each macroblock in the interframe, hand the macroblock over to FFmpeg’s libavcodec facility to work its motion estimation magic. I may be making a huge assumption here, but I’m hoping that I can pass lavc a macroblock along with 1 or 2 reference frames (previous frame and golden frame) and ask it to use its selected ME algorithm to search on a half-pel grid and find the best coding mode. The macroblock could be unchanged from the previous frame, or from the golden frame. It could use a fragment offset with a motion vector based on the previous frame or the golden frame. It could also reference a fragment from the previous frame but using one of the last 2 motion vectors. In the most complex case, the macroblock could use 4 separate motion vectors, one for each Y block, while all 4 are averaged together for the 2 C planes. And if nothing else will do, it could be declared that the macroblock needs to be intracoded, just like in a golden frame. One more thing, though– not all of the fragments in the macroblock have to be coded. The encoder can decide that a fragment is similar enough to the same position in the previous frame to warrant leaving it alone. But if a fragment is coded, it must go along with the same coding mode as the other coded fragments in the same macroblock.
Of course, VP3, like many other codecs, does not require exact matches for motion estimation. Instead, find the best possible block and code the residual difference. Through this process, the encoder will be tracking motion vectors and coding modes for each macroblock. For the 6 constituent fragments of the macroblock, if coded, perform the transform on either the raw samples or the residual, then the zigzagging and DC reduction processes as outlined in the golden frame method. Then…
…it’s time to pack it all up into a bitstream.
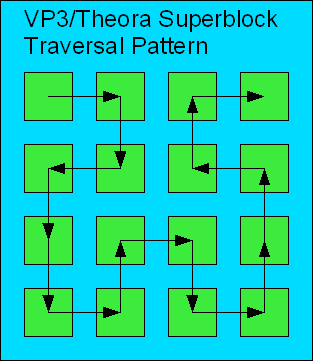
First, write out the frame header (it’s only a single byte this time). Then, pack information about the coding status of each superblock in the frame. A superblock can either be fully coded (each fragment changed), partially coded (some fragments changed), or not coded at all (entire superblock is copied from previous frame). First, pack all of the partially-coded superblocks. Any remaining superblocks that are not partially coded must, by process of elimination, be either fully coded or not coded at all. Pack information about whether the remaining blocks are fully or non-coded. Then, if any of the superblocks are partially coded, pack information about which fragments inside each superblock are coded (remember the Hilbert pattern for superblock traversal).
Next up is the macroblock coding mode information. Similar to the process for finding the optimal Huffman tables for VLC coding, some statistics must be gathered for macroblock coding modes because there are a number of different “alphabets” (as the VP3 scheme calls them) which arrange the coding modes in different orders within a list. The modes at the front of the list take fewer bits to code than the modes at the end of the list. Alternatively, if there is a more or less even distribution, the encoder can specify that each coding mode should be encoded with 3 bits (8 possible modes).
Then there are the motion vectors. Nothing too fancy here; this is probably the most straightforward segment of the bitstream encoding. Just march along the macroblocks and if the coding modes demand any motion vectors (new motion vectors, not referring to the motion vectors used for previous blocks), encode those with the variable bit scheme that VP3 uses for motion vectors.
Finally, there is the coefficient data. Pack it up the same as would be done for a golden frame (stated with the same deceptive simplicity as in the previous post on the matter).
Further Reading: